Painting, Keras Style
iainhaslam.com/slides

Aim

Content

Style
Big Picture

- Start with a random-noise output image
- Using image recognition, quantify the style and content differences between inputs and ouput
- Use a standard optimizer to minimize those differences, iteratively
Technology Stack
(easier in this direction)
- Powerpoint slides
- Keras
- Tensorflow
- Python (i.e. without the above DNN libraries)
- CuDNN and CUDA
- The hardware stack: GPU / CPU, Transistors, Physics
(generally more flexible in this direction)
Method
- The 2016 paper is here - see Fig 2
- Uses a pre-trained ConvNet (VGG19) - a DNN optimised for image recognition
- … that was trained (not by me) on > 1 million samples from image-net.org
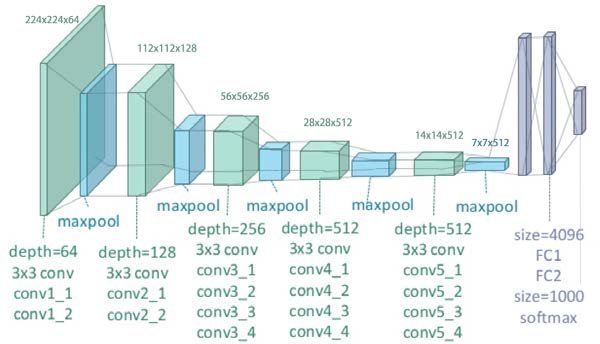
Images taken shamelessly from Wikipedia article on ConvNets.
Method
The method minimizes the loss function - which checks how close to the content and style the optimised image is getting.
$L = \alpha L_{content} + \beta L_{style}$
# The main loss function - mixes style and content
loss = beta * content_loss + alpha * style_loss
#Use the Adam optimizer to minimize the difference between the target
#image and
# 1) the content representation which is stored in one layer of the CNN,
# 2) the style representation which is stored in multiple layers of the
# CNN - each layer considers styles over different areas.
optimizer = tf.train.AdamOptimizer(2.0)
# Compute and apply gradients to optimize for minimal `loss`
operation = optimizer.minimize(loss)
for it in range(iterations):
# ... progress reporting code omitted ...
sess.run(operation)
mixed_image = sess.run(model['input'])
save_image(output_filename, mixed_image)
Style loss for a single layer is
$E_l = \frac{1}{4N^2_lM^2_l}\sum{(G - A)}^2 $
… and they are summed according to heuristically-determined (guessed at and tested) weights:
$L_{style} = \sum_{l=0}^L w_l E_l $
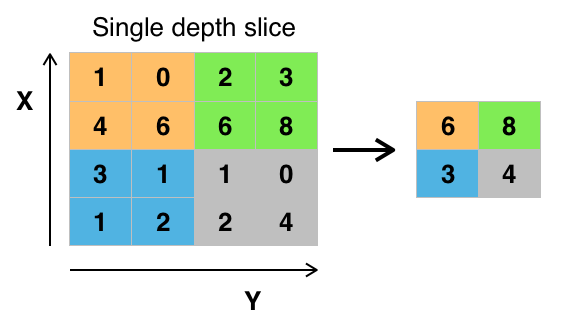
def _style_loss(a, x):
"""Calculate style_loss for a single layer."""
# Number of filters
N = a.shape[3]
# Area of feature map
M = a.shape[1] * a.shape[2]
# Style representation of the original image
A = _gram_matrix(a, N, M)
# Style representation of the generated image
G = _gram_matrix(x, N, M)
style_loss = (1 / (4 * N**2 * M**2)) * tf.reduce_sum(tf.pow(G - A, 2))
return style_loss
There are lots of variables. To keep things comparable, I’ll be using this familiar view as the content for style transfers. Compare the shapes of the moon.
Content
Style
There are lots of variables. To keep things comparable, I’ll be using this familiar view as the content for style transfers. Compare the shapes of the moon.
Content

Output
Wait, you mean some Instagram-a-like “make your photo look like art” thing? Not really - these are fotoram.io - mosaic, picasso, the scream all have the feel of a filter overlay with edge-detection.





What about big bold colours?

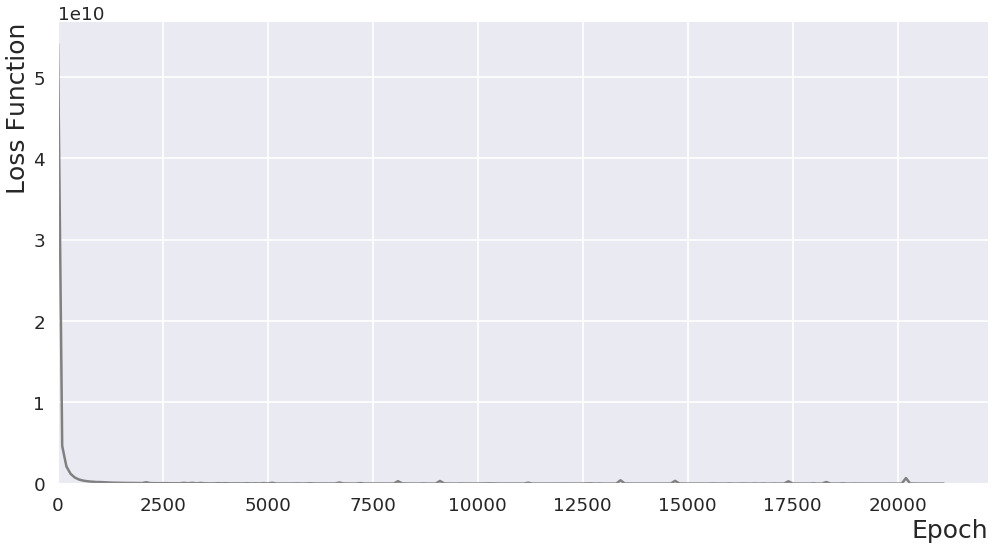
Loss function (aka objective function) vs epoch
Some of the increasing losses (a feature of SGD) are just discernable in the animation
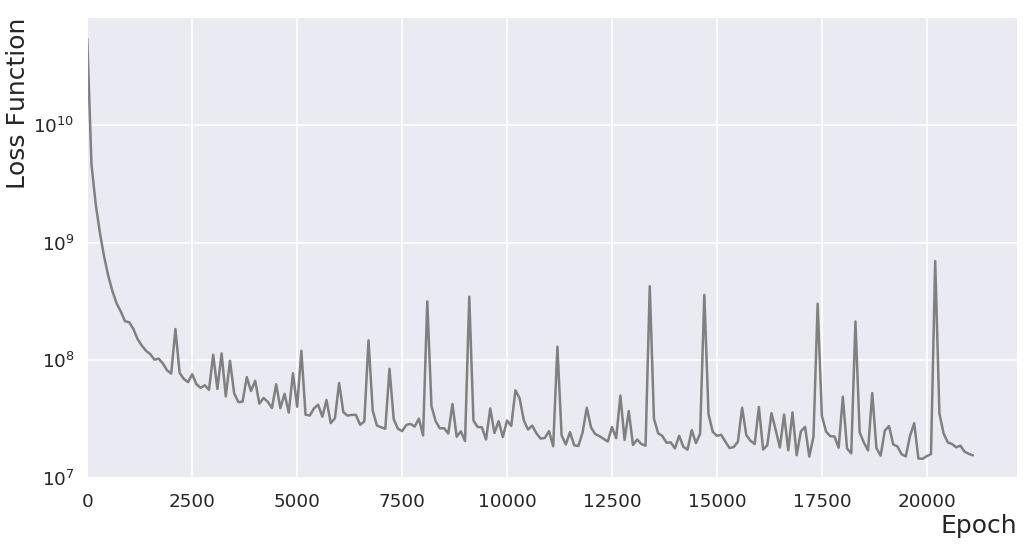
Loss function (aka objective function) vs epoch
Some of the increasing losses (a feature of SGD) are just discernable in the animation



Needs less white?


Still needs less white?


With apologies to the bear.


What about this as a style?
How well will this transfer?

What about this as a style?
How well will this transfer?

Hulk Smash.

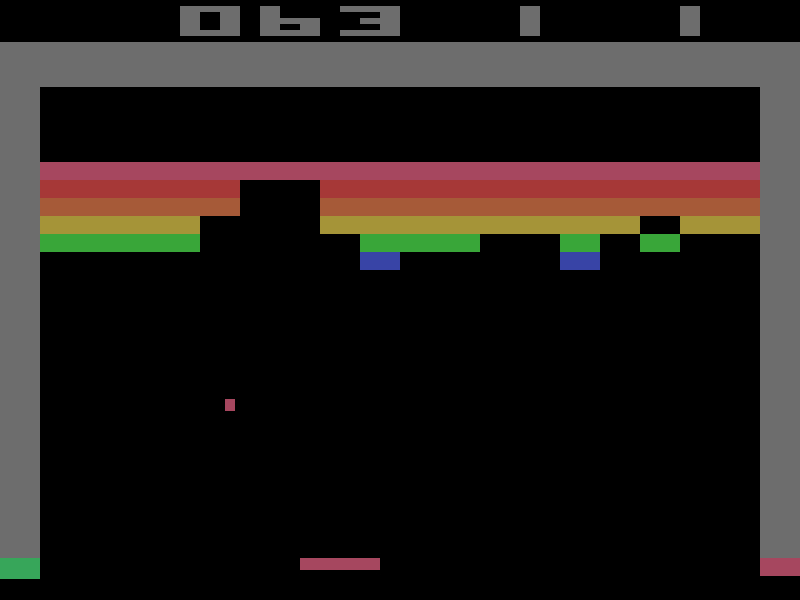
Breakout after 23500 iterations. Grey goo.

Breakout after 99900 iterations. Not better.
Swap them around
Can I transfer the style of a photograph onto a painting?

style
content
Answer: No.


This dappling is art, not compression artifact.

This dappling is art, not compression artifact.


The style in this example is an abstract canvas by our colleague Richard Hall.
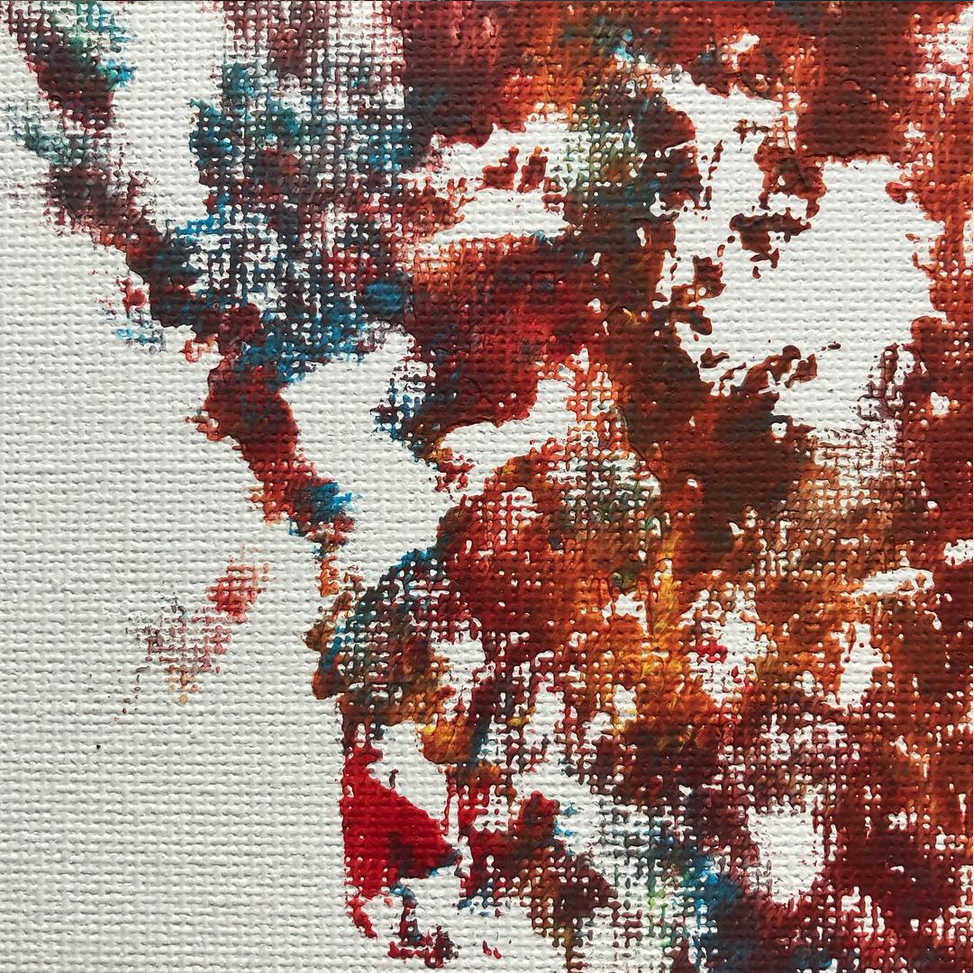
The style in this example is an abstract canvas by our colleague Richard Hall.

Generation time scales (essentially) linearly with number of pixels.

Church at Auvers



Return of the loss function
$L = \alpha L_{content} + \beta L_{style}$

Influence of initial image

Flickering due to differing noise in starting image.
Flickering due to non-deterministic optimizer.
What was the point?
- This stuff is easy and fun - try it out
- Don’t let fuzzy descriptions of “how it works” put you off. Writing a good optimizer takes a team of PhD-trained people years. Using the libraries is not so difficult.
- If you’re stuck, I’m happy to help. So is m’colleague Lee Bowyer
- If not Keras, try nltk or the OpenAI gym, …

This is not a cup of coffee (after 100, 300, 3300, 6500 and 30000 epochs)